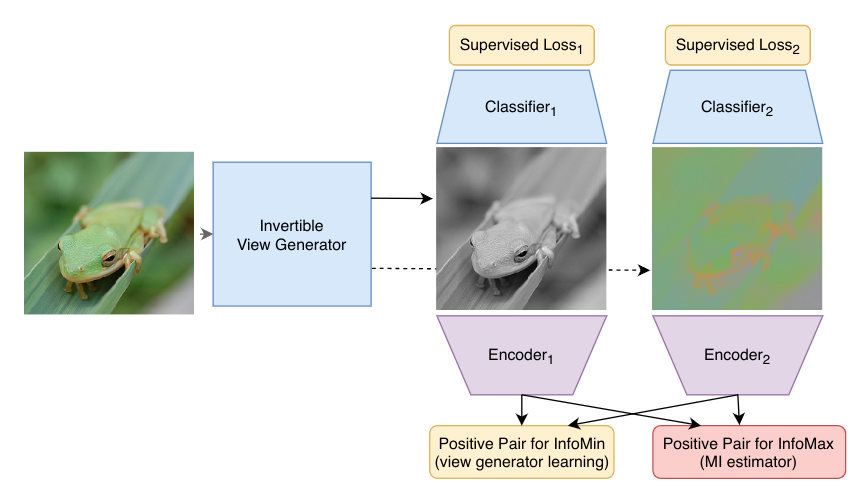
Figure 1: Constructing views for contrastive learning is important. But what are good views? We hypothesize good views should be those that only share label information w.r.t the downstream task, while throwing away nuisance factors, which we call InfoMin principle.
Abstract
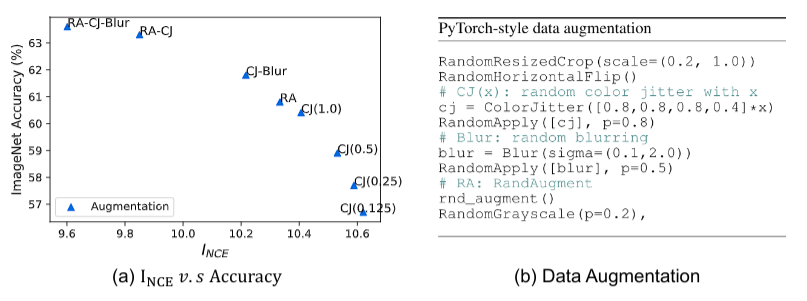
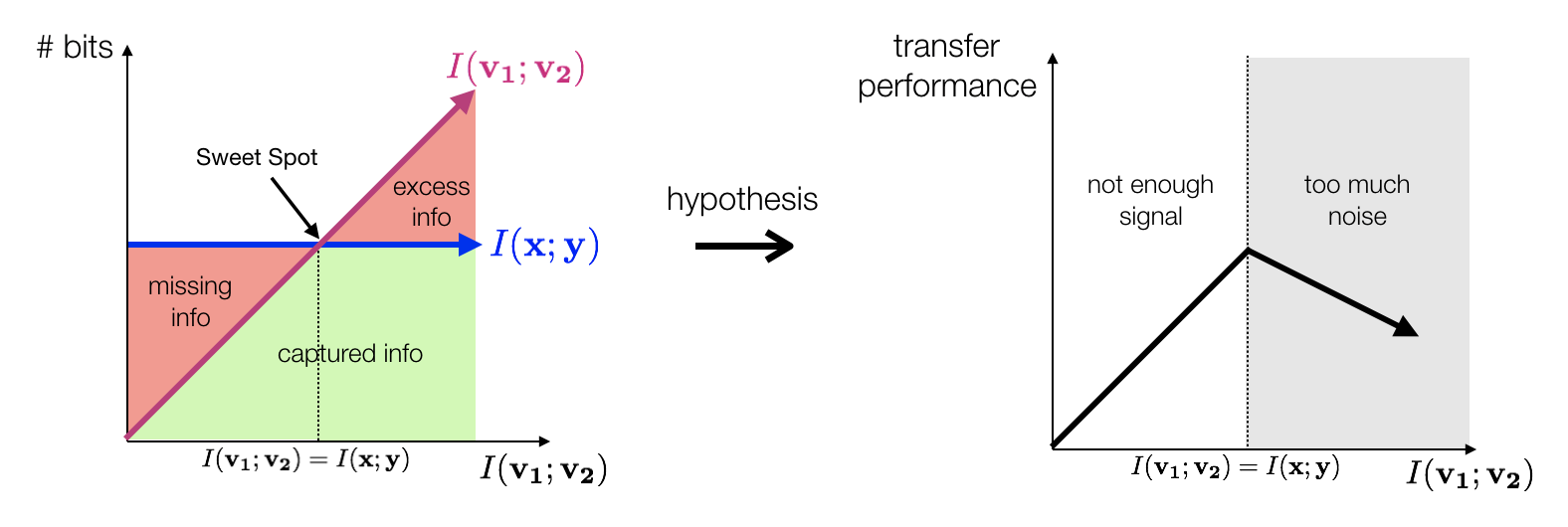
Contrastive learning between multiple views of the data has recently achieved state of the art performance in the field of self-supervised representation learning. Despite its success, the influence of different view choices has been less studied. In this paper, we use empirical analysis to better understand the importance of view selection, and argue that we should reduce the mutual information (MI) between views while keeping task-relevant information intact. To verify this hypothesis, we devise unsupervised and semi-supervised frameworks that learn effective views by aiming to reduce their MI. We also consider data augmentation as a way to reduce MI, and show that increasing data augmentation indeed leads to decreasing MI and improves downstream classification accuracy. As a by-product, we also achieve a new state-of-the-art accuracy on unsupervised pre-training for ImageNet classification ($73\%$ top-1 linear readoff with a ResNet-50). In addition, transferring our models to PASCAL VOC object detection and COCO instance segmentation consistently outperforms supervised pre-training.